
Code Review Processes
January 09, 2015
Pushing code to production without a review process in place, to me, feels like a game of Jenga. The code could be completely fine, but there’s also that chance that someone’s going to move the wrong piece and everything will come crashing down. Having any sort of review process or tooling in place can greatly reduce the chance you’re going to ship something risky, whether it’s a continuous integration service, peer code reviews, quality assurance reviews, or a combination of all of these solutions.
The Program Smith has Grown Beyond Your Control
At my job at Think Through Math we have an engineering team of about 18 developers, two of which are QA specialists. This is a lot of people (relatively speaking) to be working on code at the same time. We have a few various different services in our architecture, so not everyone is intimately knowledgable of every corner of the code. We have some people who prefer to work in the front-end, some who focus on data warehousing and reporting, and others who hack away at the back-end Ruby code. We all tend to mix and match with pairs regularly to try to spread our knowledge around, but the fact remains that we still have a number of people working on different projects at any given time, and no one person can hold our entire system in their head.
I know we aren’t alone in this area - there are other developers out there in similar situations. Some are simply trying to work on their app day-to-day, some are trying to break up their monolithic Rails app into smaller services, and some are on legacy rescue projects. Regardless of the type of project, each one could greatly benefit from sort of review process being in place. Day-to-day work could verify that everything is going to keep working while making changes or adding features, monorail breakups could ensure that each new service retains functionality but the code is of higher quality and separated correctly, and rescue projects can ensure that needed functionality persists while areas of the code beging to follow new guidelines. Even better, under the right process some of these things can be automated.
The Current TTM Review Process
Throughout the numerous iterations of our review process at Think Through Math I can’t remember a single one flat out “not working”, but some were more effective than others. The latest iteration seems to be the best to date (as one would hope), but still could be improved. In a later post I’d love to explain our new method of coming to agreements and changes to our processes, but that’s pretty out of scope for this post. Here is a brief rundown of how our current review process works.
Code Review
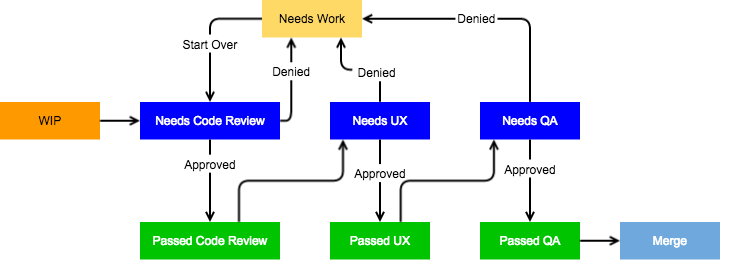
First the developer, or typically a pair, completes a bugfix, feature, or refactor and pushes the code up to GitHub. If they’re pushing just to let our CI server run the test suite on their branch, they will use our WIP label to let other developers and bots know that no actions need to be taken at this time. During this time (and anytime code is pushed to the PR) our Hound service will run and check our code styles to make sure that the code that has been submitted is up-to-par with the styles we’ve selected.
Once the code is ready to go the developer will attach a Needs Code Review label to the PR. She or he will also include complete instructions as a checklist on how QA should test the PR. At given intervals our helpful chat bot, mathbot will come through to check for PR’s with the Needs Code Review label, and then assign two other developers to review the code. In the event that one of the reviewers isn’t comfortable reviewing an area of code they haven’t been in before, they simply request for someone else familiar with the code to swap PR’s with them in our chat room.
We typically ask our developers to review the code pretty thoroughly rather than simply acting as human linters or compilers. Straight from our process definition page, the requested style of review is:
- Be inquisitive and look into why the author of the PR did things certain ways
- Look for flaws in their logic; reversed booleans, potential bad selection of objects, type mismatches
- Look for clear naming and intent of code
- Look for areas that could be optimized. Micro-optimizations aren’t always needed, but some things should be avoided
- Accidental DB calls inside of loops
- Heavy work inside of loops if it can be avoided
- Not caching or memoizing results of heavily used and expensive operations
If one or both of the reviewers feel that the code could use some tweaks, they will leave inline comments in the Pull Request on GitHub so that the developer has a clear point of reference for which areas of code were questionable. The reviewer will then remove the Needs Code Review label and replace it with our Needs Work label, signifying that the developer(s) should review the comments and either implement the needed changes or justify why they’ve chosen to write the code that way.
An important thing to note here is that all comments are done in a very respectful and positive manner. We’re never out to judge each other. We’re here to help each other write the best code possible and keep the integrity of our system together. Self-improvement is a common goal we all share on the team, and being a company about learning, we’re all about helping eachother new techniques and practices.
After the requested changes have been made or justified, the developer will remove the Needs Work label and reflag it to Needs Code Review so that the reviewers know they have more work to do. Once they both sign off on the changes, the Needs Code Review label will be appropriated flipped to Passed Code Review to signal that no more review is needed. The Needs QA flag will then be appended assuming that UX review is not needed.
UX Review
Our product hits a very diverse audience - students, school faculty, administrators, etc., so we are very conscious of our copy changes and UI/UX style changes. As such, if we perform any changes to the front end of the system that could change the appearance of something on the site we need to apply a Needs UX label to our PR in order to have someone from the UX team review our changes. This step is generally done simultaneously with the code review process since if UX needs something to be changed it may affect the code. If changes need to be made they remove their label and set it to Needs Work, the same way that is done for code review. Once all is well they will remove the Needs UX label and apply the Needs QA flag.
QA Review
The QA team is small, but heavily relied upon to ensure our code meets the requested business requirements and does not fall apart at first usage. We link our PRs up to stories from our project management tool so that the person QA'ing the PR can quickly reference what the acceptance criteria is, along with goals and nuances, while they try to break it. They use the specs provided by the developers on what to test, then use their own abilities to try to creatively blow up the system. If something broke or did not meet acceptance criteria, they’ll once again remove all labels and apply the Needs Work label, which almost always will force a new code review (usually just on the changed parts) once the changes have been applied by the developer. Once everything is complete and it functions properly, the code will receive the Passed QA label and then finally get merged into our release candidate branch. From here it will eventually be promoted to master and pushed up to production once QA and the product team have determined what features and fixes should go into a release.
Here is a flow chart if all of that label talk was confusing for you.
Why?
If this seems like a lot of process, it’s really pretty minimal in real world usage. The entire workflow can even be completed in as little as ten minutes if it’s a small review and a feature that needs pushed ASAP, but typically it’s longer and not rushed. Everything flows together naturally now and it ensures that we have three different people at least look at our code from different perspectives and ensure that it is high quality and does what it claims. This helps us keep our codebase and tests clean, readable, and self-documenting.
The benefits outweigh any potential cons of feeling like you have a Process with a capital P. We release fewer bugs, we are happy with the code that goes into the repositories, and we have people help use improve daily. I cannot stress how many times a second set of eyes has prevented a dumb error or performance degredation in my own code, and QA has saved me countless times in cases I hadn’t checked. I never feel like any comments or criticisms are made with malice or judgement, just genuine care in keeping the code clean and helping me fix mistakes, clean my code, or learn something new.
tl;dr
Create some of sort of review process at your job, or take time to analyze, review, and improve your existing strategy. Iterate on it and be open to potential changes, because the next idea may improve your results even further. Having both software and real humans review your code will save you from releasing silly mistakes to production or littering your codebase with unmanageable code.